[딥러닝] Optimizer의 종류
- 2024년 3월 24일
- 2분 분량
1.(Batch) Gradient Descent:
가장 기본적인 경사하강법 알고리즘이다. 모든 학습 데이터를 통해 average loss를계산한다. 그리고 그 값을 파라미터로 미분하고 업데이트 한다.

하지만 이 원시적인 모델은 여러가지 단점들이 있다:
매우 느리다. 학습 할 때 마다 모든 데이터를 사용하기 때문이다. 특히 데이터가 클 경우 계산 양이 너무 많다.
Local minima, 혹은 saddle point에 갇힐 가능성이 있다. Hyperparameter인 learning rate의 영향을 너무 많이 받는다.
뒤에 설명하는 모델 알고리즘은 모두 위의 문제를 보완하기 위해 고안 된 알고리즘이다.
2. Stochastic Gradient Descent:

Batch GD의 계산량을 줄이기 위한 알고리즘이다., SGD는 한 번에 하나의 데이터만 사용해서 업데이트를 한다.
매번 데이터 하나에만 의존하기에 불확실성이 많다. 고로 converge하기도 어렵다.
3. Mini-batch Gradient Descent:
BGD와 SGD간의 중간지점을 찾은 알고리즘이다. 전체 데이터를 쓰지도 않고, 오직 하나의 데이터를 쓰지도 않는다. 전체 학습 데이터 중 일부만 랜덤으로 샘플링 해 업데이트를 진행한다.
4. SGD with momentum

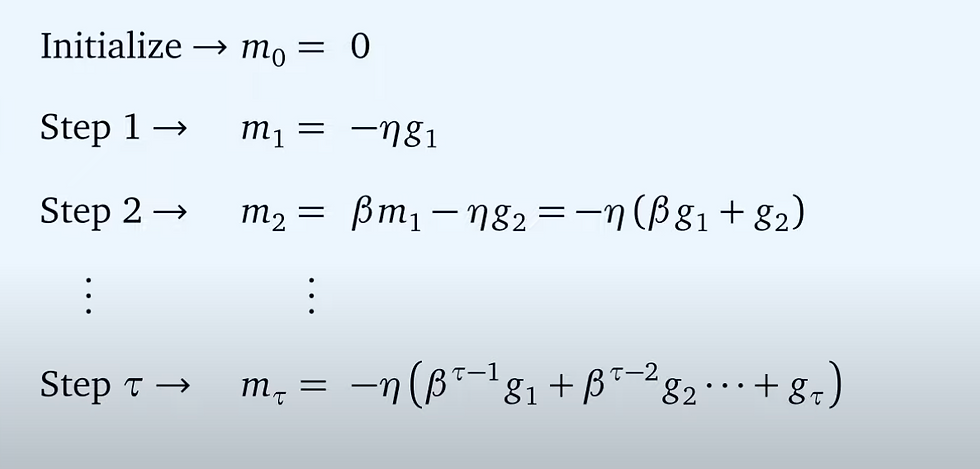
사실 momentum보다는 inertia가 더 적절한 표현인 것 같다. 고정된 보폭으로 야금야금 가는 것은 너무 느리니, 최적화가 되었던 관성을 따라서 가자는 아이디어이다. 이를 통해서 더 빠른 학습이 가능하며, local optimum도 벗어날 수 있다.
여기서 momentum이라는 것이 추가 되었는데, 여태껏 학습 되어온 gradient의 polyak average로 볼 수 있다. beta 값이 높을 수록 종전의 정보들을 더 많이 고려한다고 볼 수 있다.
다만, 해당 방법의 단점은 global optimum에 도착했음에도 잘 수렴하지 않고 오버슈팅이 벌어질 수 있다는 것이다.
5. Nestrov Accelerated Gradient

종전에 모멘텀보다 한 층 진보 된 알고리즘이다. Momentum을 언덕을 내려가는 공으로 비유하면 눈을 감고 내려가는것과 같다. 언덕을 다 내려가고 다시 올라가기 전에 미리 이를 알고 속도를 줄이자는 직관에서 만들어 진 것이 NAG이다.
그걸 어떻게 구현할까. Momentum에서는 현재 위치에서 기울기를 계산했다. NAG는 현재 위치가 아닌 미래 위치를 추정하여 거기에서 기울기를 구한다.
1. 현재 운동량을 가졌을 때의 미래 위치를 찾는다.
2. 미래 위치에서의 기울기를 구한다.
3. 기울기를 이용해 미래 위치를 다시 계산한다 (이미지의 partial update 부분).
라는 식인 것이다.
6. Adagrad

Adagrad는, 많이 업데이트 된 파라미터는 조금 덜 수정하자는 아이디어에서 출발했다. 업데이트가 진행 될 수록 G값은 올라가고, 업데이트는 줄어든다.
하지만 이 경우, 학습이 진행 될 수록 느려지는 문제가 발생한다. 운이 안 좋은 경우, global minima에 다다르기도 전에 필요이상으로 학습이 느려질 수 있는 문제가 존재한다. 그래서 고안된게 RMSProp이다.
7. RMSProp

RMS는 gamma를 추가해, 지나간 gradient 값이 어느 정도 망각이 될 수 있도록 설계했다. 이 덕분에 학습의 보폭이 시간에 따라 무조건적으로 줄어가는 대신, 최근 값에 따라 다시 오를수도 있게 된다. Gamma값이 낮을 수록 현재의 gradient가 미치는 영향이 커진다.
8. Adam

Momentum과 RMSProp을 혼합한 알고리즘이다. 두 가지의 장점을 고루 취한 것이라고 보면 될 것이다. 실제 현업에서 가장 많이 사용하는 알고리즘이다.
9. Nadam

Adam이 Momentum과 RMSProp을 혼합한 알고리즘이었다면, Nadam은 NAG와 RMSProp을 혼합한 알고리즘이다.
댓글