[LLM] Reasoning LLM - literature review
- 2024년 9월 13일
- 6분 분량
최종 수정일: 2024년 12월 11일
Migrated here
Core idea: PRM(process reward model) works better than ORM(outcome reward model)
One of the solutions to mitigate hallucination issue is to ask the same question for multiple times and find out the best one. Here, there should be a judge that determines which answer is the best.
Note: The paper is about making a better verification model. It didn't deal with tuning the generator model using the reward model.
One detail: PRM works like: PRM(sequence of the token in each step) = "positive," "negative," or "neutral". During inference, we compute the softmax of the probabilities of these three category tokens and get the score.
Insights: Assuming o1 uses an MCTS-like approach. Then something like this PRM could be the reward model.
Core Idea: The paper explores methods for optimizing inference in terms of computational cost, but the primary focus should be on the methodologies used during inference.
Two broad approaches to inference are highlighted:
Using a verifier model during inference.
Not using a verifier model (self-verifying), where the generator revises its own intermediate steps.
Approaches Involving a Verifier Model:
1. Best-of-N (Verify Step by Step) – Generate multiple solutions and use a verifier to select the best one.
2. Beam Search – Recursively generate intermediate answers and prune using a PRM (Process Reward Model).
3. Lookahead Search – Similar to MCTS, it estimates long-term rewards heuristically and backpropagates. Interestingly, this method underperforms beam search, likely due to PRM limitations.
Approaches Without a Verifier Model:
Standard SFT (Supervised Fine-Tuning), where a generator outputs answers that reason step-by-step based on training data without external verification.
Training Data Concerns:
The paper's method of creating data for SFT involved:
1. Generating 2048 responses for each math question.
2. Selecting wrong answers that were close to the correct one using a metric like BLEU or Levenshtein Distance.
3. Concatenating these wrong answers and the correct answer to form the final QA pair for fine-tuning the model.
Key Insights:
The Lookahead Search underperforming compared to Beam Search is counterintuitive. The paper attributes this to PRM’s inadequacies, which may warrant further investigation.
Training data generation methods could be improved, as the current process lacks steps that involve verification or transitions to alternative methods. Exploring a better way to collect and generate training data might open up new research avenues.
Potential Research Direction:
One idea is to create a single LLM that reasons during inference without needing a verifier model, which could significantly reduce computational costs. The goal would be to fine-tune the model to mimic the reasoning process, avoiding the need for multiple trajectories during inference. If this approach achieves comparable performance, it would be a meaningful contribution to the field.
Additional Notes:
The current method for fine-tuning the revision model shows improvements, but the methodology for training data creation could be questioned, especially given the surprising performance gain with limited data collection resources.
A cited CMU paper suggests a better way to generate training data, which could be worth exploring further.
Core idea: Fine-tune a single LLM that does self-improve. Take query x, previous answers and feedback as the state, and action becomes the next step.
Good thing: It uses LLaMa 2 7B model, a weak FM, implying less burden in cost. Such a setting also allows the use of "more superior model"
Concern: The answer it provides doesn't have a sequential reasoning. It is like give the whole answer -> get the feedback -> next whole answer. In section 5, it says that previous answers and feedback makes a distributional shift, but intuitively, this is not how we reason. Their current approach is like "do it until you make it", but I won't give you a hint or clue to resolve this problem. This is very inefficient. Rather than that, it is better to have a tutor guiding in the intermediate steps, illustrating why it is wrong.
Maybe what we can do is that: Find out a math problem set that can be easily resolved by stronger model but can't be done well by weak models, and let the stronger model give guidance on weaker model. If we see an obvious improvement in the performance after fine-tuning we can suggest a possibility that even a stronger model can resolve harder problem if there are enough human-annotated data.
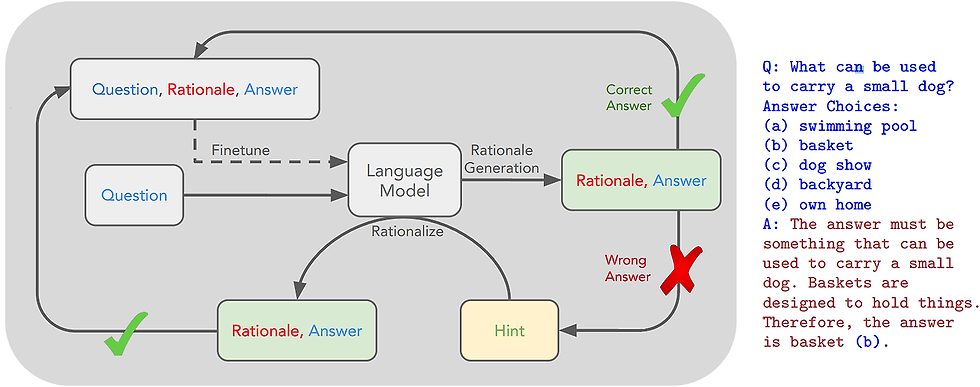
Core idea: Let the LLM give reason before answering, and collect those data (only the correct ones)for fine-tuning. If the LLM answers it wrong, give the correct answer and let it infer again. Then, for training set, exclude the part that you gave hint.

Core idea: A prompting skill that enables an LLM to choose the module appropriate for a certain task (SELECT), rephrase the module to a task-specific way (ADAPT), and plan the reasoning structure.
Personal Thoughts: It is more like an agentic workflow idea to let it "SELECT" the module.


Core idea: Like alphago, they do sequential reasoning separated by the unit of thoughts. However, they do not use any pre-trained PRM. They directly use another LLM as the value function.
Core idea: Generalized framework for CoT, SC-CoT, and ToT. Allows splitting, merging, revisiting, and removing the nodes.
Note that the graph structure should be predefined by the developer. I personally don't like it because this is not a generalizable approach, but more like an agentic workflow that need customization of human developers.


Intuition: ORM can't figure out with step of reasoning was wrong; PRM is expensive. We use reverse curriculum reinforcement learning to take the advantage of both.
Algorithm: There is a step-by-step ground-truth. We mask different phases of the reasoning to make the dataset and do reinforcement learning.
Concern: According to the paper, R3 enables generalization by having different levels of difficulties of problems (or different extent of masking). However, it still somewhat has the problem of overfitting imo, as there is only one trajectory of the ground truth for each question.

Core idea: DCoT - For each question, they collect multiple CoT, concatenate them with the last one being the correct answer, and conduct standard supervised fine-tuning.
Concern: Marginal improvement of performance of performance. Also, pretty similar to RISE. Simply giving multiple answers together is not smart. No verifying steps and judging right or wrong is addressed.


Core idea: SFT only collects successful CoT trajectories. ReFT deals with both successful and unsuccessful trajectories, setting different rewards for different settings.
On the Diagram of Thought (Seems like an incomplete paper)

Core idea: Let a single LLM propose, criticize, and summarize. (VERY SIMILAR TO OUR IDEA)
They collect data and do fine-tuning. However, details of the fine-tuning process is not mentioned in the paper.
They don't even have an evaluation section...


Core idea: Inner dialogue agent (teacher model) & LLM agent (student model) talk with each other iteratively and get the final answer.
No specific prompt or fine-tuning processes were mentioned.
They never collected the conversation history and fine-tuned to use it to a single model.
We might add the concept of "module" here??
Problem to solve:
1. Collapse: Settle down to initial response and do minor changes only
2. Distributional shift: Training dataset not from the LLM itself, causing distributional shift.
Solution: Use 2 stage online reinforcement learning without external source of data (check diagram below)
Stage 1: constrain to the base model with KL divergence in response 1.
Stage 2: maximize shaped reward for second reward, aka the additional gain.

Training Language Models to Self-Correct via Reinforcement Learning
GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements
Advancing LLM Reasoning Generalists with Preference Trees
LLMs cannot find reasoning errors, but can correct them given the error location
Generating Sequences by Learning to Self-Correct
To read:
Q* / Strawberry: https://reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
https://isamu-website.medium.com/understanding-the-current-state-of-reasoning-with-llms-dbd9fa3fc1a0
ideas:
ToT -> DFS를 하나의 선형적 flow로 취급 (LLM의 autoregressive한 성질과 부합) -> fine-tuning, 혹은 RL
ToT나 GoT등 구조화 된 생각 대신 dual-agent의 conversation을 따와서 트레이닝. 대화의 형식이 플래닝에 좋지 않을까 하는 생각.
댓글